
In part 2 of this series I talked about how retention was calculated and worked. In part 3 of this series I would like to discuss how archiving works in Log Insight as it is probably a little different than you think.
![]()
Note: All information in this post comes from a 2013 VMworld Session on Log Insight called: Deep Dive into vSphere Log Management with vCenter Log Insight
What is Archiving?
Before describing how archiving works, it is important to understand what archiving is, how it is configured and what Log Insight expects. Archiving is used to store events for longer than the retention period of Log Insight. The primary use-cases around archiving are compliance and governance — historic data retention. Today, archiving can be configured from the Administration > Archiving section:
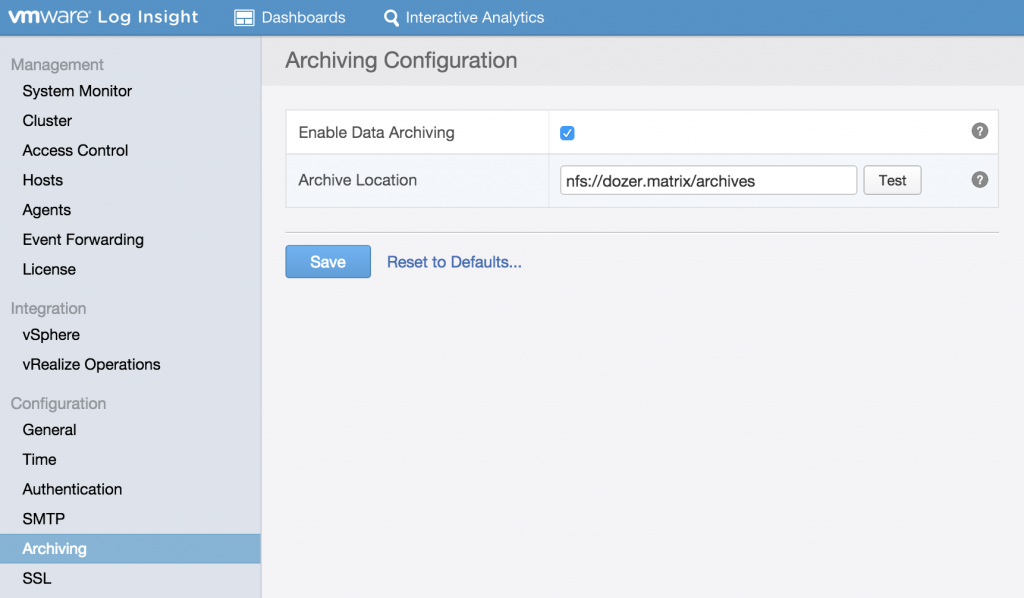
The prerequisites for configuring archiving are:
- The NFS partition must allow reading and writing operations for guest accounts
- The mount must not require authentication
- The NFS server must support NFS v3
It is important to understand how Log Insight leverages the archiving location: it writes to the share, but it does not manage the share. More specifically this means Log Insight does not read — other than to check free space — and does not delete from the NFS share. This means the user is responsible for ensuring the share does not fill up. Log Insight will archive indefinitely.
Warning: Log Insight does not manage the NFS location — the user is responsible for ensuring enough free space and deleting old archives.
How Archiving Works
So how does it work? Well, this picture represents the process pretty well:
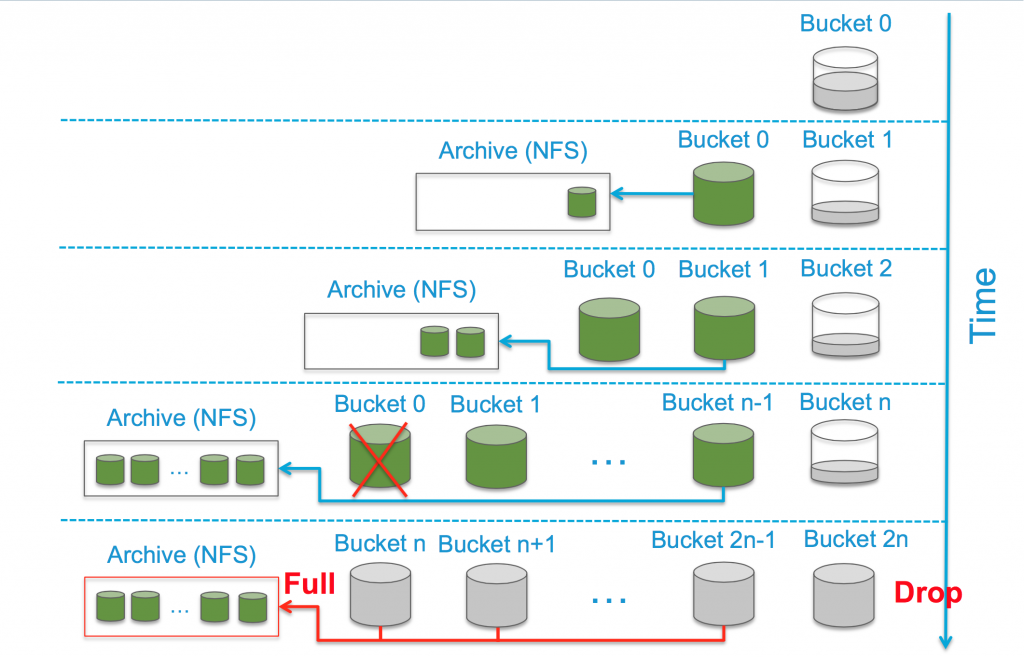
Starting from the top, with a new Log Insight instance you would have a single bucket (Bucket 0) where events are being stored locally and new events would be added to the bucket — meaning the bucket is r/w — until the bucket reaches 1GB in size. Once the bucket reaches 1GB it will be sealed — meaning it becomes r/o — and a new bucket will be created for new events (Bucket 1).
Assuming archiving is configured on Log Insight then as soon as a bucket is sealed it is marked ready to be archived and the archiving process begins. Once the archiving of the bucket succeeds the bucket is marked as archived (represented by green buckets above). At this point you have a sealed and archived bucket locally on the Log Insight appliance and you have an archive on the NFS location containing the compressed logs.
Important: If archiving is not enabled then when a bucket is sealed it is clearly not archived. If archiving is turned on after buckets have been sealed, the previously sealed but unarchived buckets WILL NOT BE ARCHIVED. In short, archiving must be enabled before a bucket is sealed.
The process of sealing and archiving buckets until Bucket N is reached. For more information on how Bucket N is calculated, see part 2 of this series. Once Bucket N is created, Bucket 0 is deleted from the Log Insight appliance and the data in Bucket 0 cannot be queried from the UI anymore — even if it is still available on the archive. In order to query archive data that has since be removed from the local retention of the Log Insight appliance, you must re-import the archive using the CLI method described here.
Important: It is NOT recommended to import archived data into an existing Log Insight instance that is ingesting data. The reason for this is because the data from the archive import will force the oldest ingested data to be deleted in order to make room. The net result may be an inability to maintain the desired retention period for events. Instead, the recommendation is to import archives into a dedicated Log Insight instance that is not ingesting events from other clients.
If archiving is configured, but the NFS destination is unavailable then a sealed bucket will remain pending for archive and Log Insight will automatically retry. If NFS is down for a long time this could mean that you have multiple sealed buckets pending archive. This is OK as Log Insight manages this overhead and when the archive becomes available will ensure that pending buckets are properly archived oldest first. With that said, Log Insight does not manage the NFS destination. This means if the NFS destination becomes full then Log Insight will be unable to archive events — though it will keep trying hoping that space has freed up. If the archive is full for longer than the retention period of Log Insight then you would get into a state where all buckets are sealed and pending archive and no new events can be ingested.
Important: Log Insight does not manage the NFS destination and if the destination remains full for longer than the Log Insight retention period then new events will be dropped!
Summary
There are several important details with retention and archiving:
- Archiving must be enabled before a bucket is sealed or the bucket will never be archived
- Archiving happens once 1GB of data has been consumed per Log Insight appliance
- Under normal circumstances data will exist on the Log Insight appliance and the archive for the majority of the retention period
- This means the archiving period must be longer than the retention period (e.g. 60 days archives, 30 days retention) or else both will contain almost the same information (e.g. days 1-30 are on the archive and on retention while days 31-60 are on the archive only)
- If the archive destination is unavailable Log Insight will retry automatically in an attempt to ensure all sealed buckets are archived (i.e. Log Insight never gives up trying)
- Log Insight does not manage the archive destination — the user is responsible for ensuring the archive does not fill up!
- If archiving is configured, but full for longer than the retention time of Log Insight then Log Insight will drop new events — do not let this happen!
- The archive must be NFS v3
In my final post, I would like to tie this series together and talk about the life of an event.
© 2015, Steve Flanders. All rights reserved.
Thanks for this very informative document. Really a lot changed in my way of thinking about Archives in a nfs mount.
Questions what i have is, do we have any procedure to delete these archived buckets in nfs mount?
Can we delete the servers by stoping loginsight and deleting the folders and files created and listed in /tmp which inturn will map back to nfs mount.. below is one such entry
sondur1nv1.*****.****.*****:/ifs/projects/loginsight/vrli2 4.0T 4.0T 0 100% /t
Why is loginsight using this /tmp while upgrading and filesystem space is very needed at /tmp?
snapshot recoverd did had upgraded version of xml which was pointing to next version.. in my case it was from 3.0.0 to 3.3.1 and snapshot should have 3.0.0 version pointing but was 3.1 and services were up but not the web console.
Any information on these will help me a lot in upgrading to latest version as we are in outdated version and not recieving any proper support to clear the nfs mounts..
Thanks,
Hey Aruna — LI write archives once and that is all. The way to delete old archives would be outside of LI. You could run some script that deletes all files older than your archive period (again LI only write once so you can use the file creation or last modification time). Not sure if I follow your upgrade issue to provide guidance.
Would I be able to log in to a LI node and clean up the NFS archive share from there?
We have IP restrictions on the NFS filer that is holding our archive, so there is limited access. I have 7 days to clean up older logs, so I was thinking this may be the most secure option. What would you recommend?
Hey Jason — if you do not have direct access, but do have access to LI then you could do it from the LI side. Mount the share and perform the operation desired then unmount the share. Given LI needs r/w access it is possible to perform the operations (though LI will not do it automatically).
Hi Steve, is it possible to retrieve logs from an archive nfs share from a specific date range?
Hey Alan — archives are based on buckets and buckets are size-based. The archive file is also timestamped. Based on this, you will know the approximate time range for the log archive. The only supported way is to import the entire archive, but you could manually uncompress and manually sort to get specific logs. I hope this helps.