
In part 1 of this series I talked about the different pipelines. In part 2, I would like to talk about how retention works. Hint: It does not involve a database and a full disk is normal!
![]()
Note: All information in this post comes from a 2013 VMworld Session on Log Insight called: Deep Dive into vSphere Log Management with vCenter Log Insight
How Retention is Calculated
Before describing how retention works, it is important to understand how retention is calculated. The Log Insight virtual appliance is made up of three virtual disks:
- Hard disk 1 = 12.125 GB = root filesystem
- Hard disk 2 = either 120 GB for xsmall/small or 270 GB for medium/large
- Hard disk 3 = 256 MB = first boot only
- Hard disk N = additional disk with a maximum supported size of 2TB
When it comes to retention, hard disk 2 + hard disk N — where there could be multiple disk Ns — are what matter. Starting with hard disk 2, the capacity is broken up into two partitions:
- /storage/var = 20GB = logs
- /storage/core = <hard disk 2> – 20GB = retention + other
If you were to add a hard disk N later then it gets added to the /storage/core partition on virtual appliance reboot. For example, let’s assume you add hard disk 4 of size 2TB then when you restart the Log Insight virtual appliance /storage/core will equal – 20GB + 2TB. A few additional important notes:
- Dynamic space addition — LVM extend — happens on virtual appliance restart only and happens automatically
- Dynamic space addition only works for the /storage/core partition, which is the partition that contains all ingested events
- To add space to /storage/core you should add a new virtual disk and NOT attempt to extend an existing virtual disk
- The maximum size virtual disk supported is 2TB today, if you add a larger disk then the LVM extend will fail and data corruption could occur
- While you could add multiple 2TB virtual disks, Log Insight supports a maximum of 2TB per virtual appliance as of version 2.5
- You should never remove a virtual disk after it has been added to Log Insight as this will likely lead to permanent data loss
Now that you understand where retention is kept and how the size can be changed, let me now cover how Log Insight uses this space. The calculation is pretty simple: retention = /storage/core – 3%. This means if /storage/core is 250GB then Log Insight will use 242.5GB of space within /storage/core for retention (possibly slightly more as described below). The remaining space is reserved for Log Insight as well. For example, the Cassandra database uses some of the remaining space.
Remember: Retention is stored on the filesystem in a proprietary, no-sql-like format. Cassandra is used for user and configuration data.
The above knowledge about retention is important for several reasons:
- Under normal operating conditions, the /storage/core partition should be mostly (97+%) full — of course a new node will start with very little in /storage/core, but over time the partition will fill up
- Log Insight does not remove stored events until the retention capacity is reached/exceeded — this means Log Insight will retain events for as long as it has space for. Also note that setting the retention notification from /admin/general is only to tell you when you are under the configured threshold and will not result in data older than the configured threshold being deleted
- Log Insight owns/manages the /storage/core partition and you should not store any data in that partition as it may interfere with Log Insight’s operation
- Log Insight will automatically delete the oldest retained events when retention has been exceeded
- The /storage/core partition will never completely fill up — assuming Log Insight is the only one writing to it — as Log Insight manages the partition and the space
Note: It is perfectly normal for the /storage/core partition to be mostly (97+%) full.
How Retention Works
So how does retention work? Well, this picture represents the process pretty well:
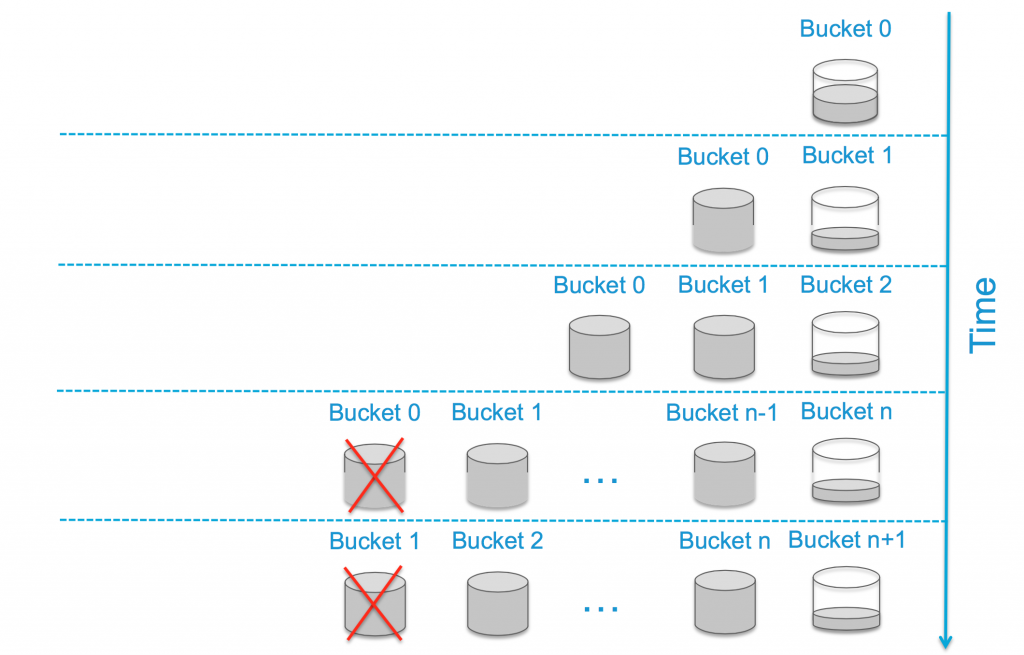
Starting from the top, with a new Log Insight instance you would have a single bucket (Bucket 0) where events are being stored locally and new events would be added to the bucket — meaning the bucket is r/w — until the bucket reaches 1GB in size. Once the bucket reaches 1GB it will be sealed — meaning it becomes r/o — and a new bucket will be created for new events (Bucket 1).
The process of creating and sealing buckets continues until Bucket N is reached. Bucket N represents when the retention — formula described above — is reached meaning no space remains for retention. To make room for Bucket N, once Bucket N is created Bucket 0 is deleted from the Log Insight appliance and the data in Bucket 0 cannot be queried from the UI anymore. The process of creating, sealing and deleting buckets continues through the life of the Log Insight virtual appliance.
Summary
Log Insight uses the /storage/core partition to store retention in a proprietary, no-sql-like format. The /storage/core partition is made of – 20 GB + where N is greater than or equal to 4. Retention is /storage/core – 3%. Log Insight manages the /storage/core partition and will ensure it does not run out of space. Under normal operating conditions, the /storage/core partition will be nearly (97+%) full. While it is possible to increase retention by adding more — not extending existing — virtual disks and restarting the virtual appliance, it is not possible to use less space than the virtual appliance has been allocated and it is not possible to reduce the size of retention today.
In my next post, I will cover how archiving factors into the retention equation.
© 2015, Steve Flanders. All rights reserved.
Very nice article, I am facing issue with loginsight storage. /storage/var got full. I tried adding new disk, as you mentioned it got added to /stoage/core but /storage/var still shows 100%.
df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 16G 2.4G 13G 16% /
udev 7.9G 124K 7.9G 1% /dev
tmpfs 7.9G 648K 7.9G 1% /dev/shm
/dev/sda1 128M 38M 84M 31% /boot
/dev/mapper/data-var 20G 20G 0 100% /storage/var
/dev/mapper/data-core 532G 444G 62G 88% /storage/core
Can you suggest how to take care of this.
Hey Shrikant — sorry to hear this. Adding a virtual disk will only extend /storage/core so this is expected. /storage/var should not ever fill up though. You will need to SSH to the virtual appliance and determine what is consuming the space on /storage/var. It is possible you have a heap dump which would indicate an issue you would need to engage with support. Let me know when you determine what is consuming the space and I can advice further.