
Log Insight 1.x supported a scale-up model. Log Insight 2.0 Beta supports clustering of Log Insight nodes. I would like to walk through how to configure clustering, what it looks like when complete, and what the benefits of using clustering are.
Creating a cluster
Any fresh deployment of Log Insight 2.0 beta will present the option of becoming a standalone node or joining an existing deployment. When joining an existing deployment, the FQDN of the master must be specified.
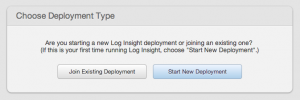
A few things to note here:
- Master refers to either a standalone node or the master node in an existing cluster.
- If the master specified is a standalone node, the standalone node will become a master and join the requesting node as a worker.
- While an IP address can be specified for the master, the use of a FQDN is recommended. The reason for this is because if the IP address of the master changes, the workers will no longer function without manual intervention.
Once a request to join an existing deployment has been completed:
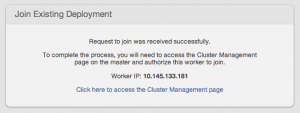
the request must be accepted on the master node to complete the two-way handshake:

Once the handshake has been completed, the master will display the new worker information
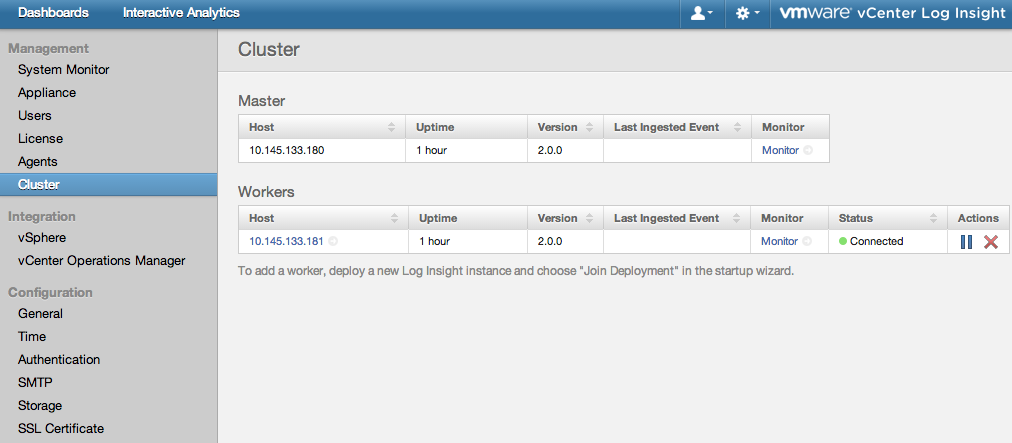
and the worker will state that the operation was successful.
Reasons to cluster
Single management point
In Log Insight 1.x, once you hit the configuration maximum of a large node you needed to deploy a new Log Insight instance. Each Log Insight instance needed to be managed separately, which may not be ideal for all environments. In Log Insight 2.0 Beta, the clustering ability makes it possible to group multiple Log Insight instances together and manage them centrally.
Ingestion HA
Another reason to deploy a cluster in addition to scale-out is ingestion HA. With a cluster in place, a third-party load balancer can be put in front of the cluster to handle ingestion of events. All Log Insight node types are capable of ingesting events and Log Insight can queries for events from the same device even if those events are on different node types. As such, it is recommended to put a load balancer in front of the Log Insight cluster and forward all events to the load balancer instead of individual Log Insight nodes. The benefit of the deployment is that if a Log Insight node goes down (e.g. hardware failure of an ESXi host running the Log Insight virtual appliance) the load balancer can direct events to another node in the cluster.
If a load balancer is not used then traffic will need to be manually balanced across each node in a Log Insight cluster. With this approach, the number of events per second needs to be considered to ensure a configuration maximum is not reached. In general, forwarding events directly to nodes in a Log Insight cluster is not recommended.
Summary
In terms of creating a Log Insight cluster, it does not get much easier than that if you ask me! In the beta, Log Insight supports up to a 6-node cluster where one node is the master and up to five nodes are workers. The use of an external load balancer is highly recommended and will allow for ingestion HA.
I will dive deeper into the scale-out features and considerations in a future post.
© 2014 – 2021, Steve Flanders. All rights reserved.
While we’re allowing 6 nodes in the beta, do we feel we’ll expand that infinitely to allow cloud scale when it goes GA or at some point in the future?
The goal is to support any sized environment so the new configuration maximums will continue to grow over time.