
Log Insight 2.0 introduced the ability to scale out in addition to scale-up. With this change, a Log Insight instance is capable of playing different roles or service types. These include:
- Standalone (available in 1.x)
- Master (new in 2.0)
- Worker (new in 2.0)
NOTE: Service types should not be confused with node types. Every Log Insight instance (or node) is capable of running any service it is a matter of what service is enabled on the node.
I would like to discuss the differences between these service types and some important considerations to keep in mind.
![]()
Inputs
Before I start, it is important to understand the inputs for Log Insight:
- The query pipeline exists to allow users to interact with data within Log Insight
- The ingestion pipeline exists to allow logs to be sent to Log Insight
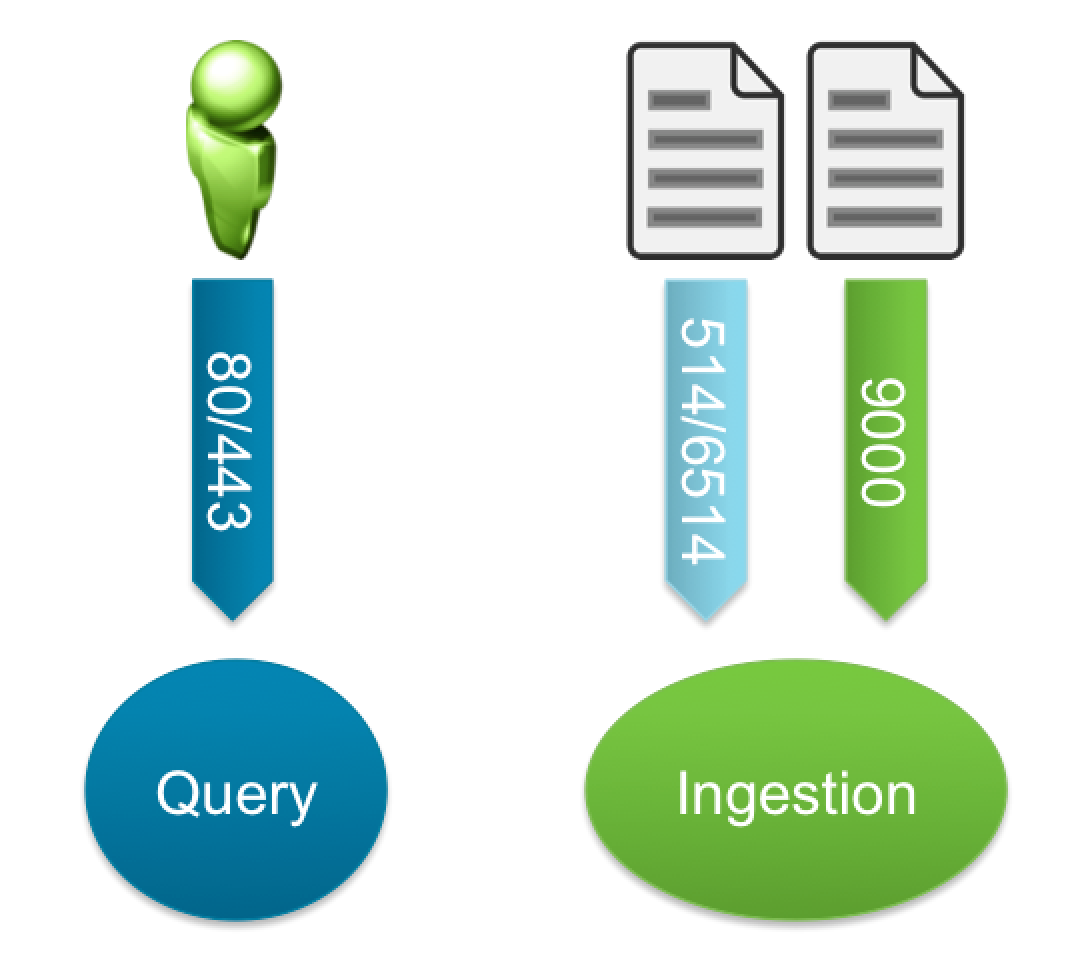
NOTE: The above image is an oversimplification as it does not lists protocols and skips port 1514 as a supported ingestion pipeline port.
Standalone
Any previous version of Log Insight upgraded to 2.0 will default to a standalone service. Upon upgrading, the instance will function as it had previously. A standalone service is a single node deployment of Log Insight.
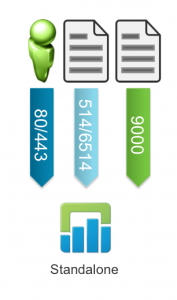
NOTE: If you have multiple standalone nodes with existing data on them (e.g. upgraded from 1.5), you cannot spin up a new Log Insight instance and create a cluster by having the existing standalone nodes join the new standalone node. In short, once the initial configuration wizard has been completed, the only change to the service type you can make is turning a standalone service into a master service.
Master
To create a cluster, see this post. In short, a second Log Insight instance is stood up and then told to connect to a master during the initial configuration. If you are just creating the cluster then the master will be the standalone instance you stood up previously. This means the standalone instance you stood up previously changes from a standalone service to a master service and the new node you stood up runs a worker service. Once a cluster has been created, all daily operations can be performed from the master’s UI. The master UI serves as the single pane of glass for Log Insight clusters. All queries against data are issued against the master, which in turn queries the workers as appropriate.
What happens if the master goes down? Today, a single master is available for all queries against a Log Insight cluster. If the master is unavailable then queries against events stored in a Log Insight cluster are unavailable. When the master comes back online the logs can be queried over again. A master is also in turn a worker, which means a master can handle the ingestion of data as well. Since all nodes in a Log Insight cluster can handle ingestion, if the master goes down ingestion of events continues assuming you have properly configured an external load balancer in front of the cluster.
NOTE: It is a best practice to configure an external load balancer in front of a cluster. For more information on load balancer configuration, see this post.
Worker
A worker’s UI only presents a minimalist administration view primarily for troubleshooting purposes. A worker’s job is to ingest/process events and present them to the master upon request.
What happens if a worker goes down? Today, logs are stored locally on a worker, if a worker goes down the logs on that worker becomes unavailable. The Log Insight UI notifies you if a worker is unavailable:

When the worker comes back online the logs are available again for query. All nodes in a Log Insight cluster can handle ingestion so a worker going down does not prevent the ingestion of events unless those events are directly pointing to the worker assuming you have properly configured an external load balancer in front of the cluster.
NOTE: It is a best practice to configure an external load balancer in front of a cluster. For more information on load balancer configuration, see this post.
Cluster
A cluster is made up of two service types: one master and up to six workers. Through the use of an external load balancer, ingestion HA is supported.
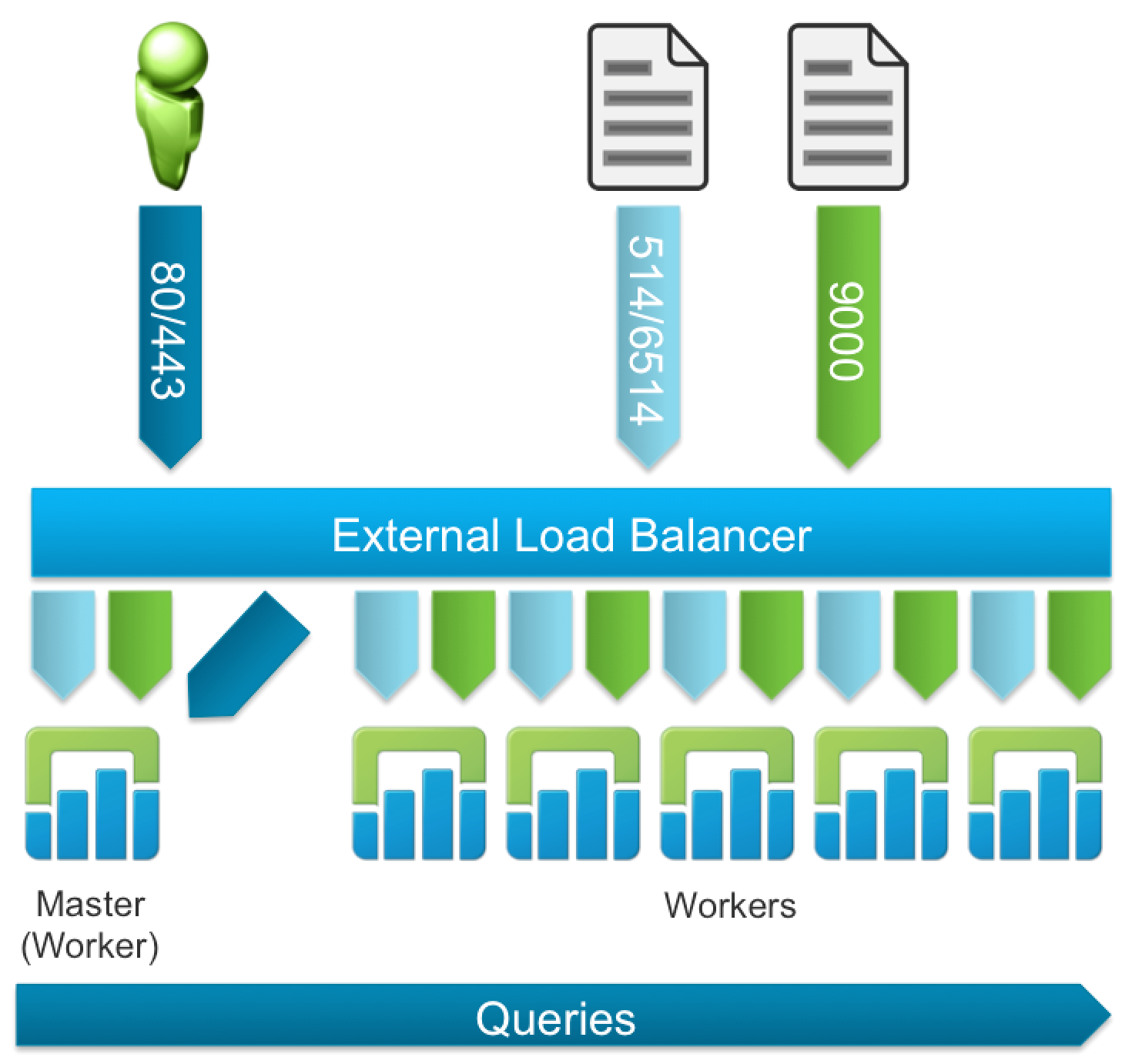
The query pipeline does not need to point to the external load balancer since the traffic can only be sent to the master. As such, the following configuration is also supported:
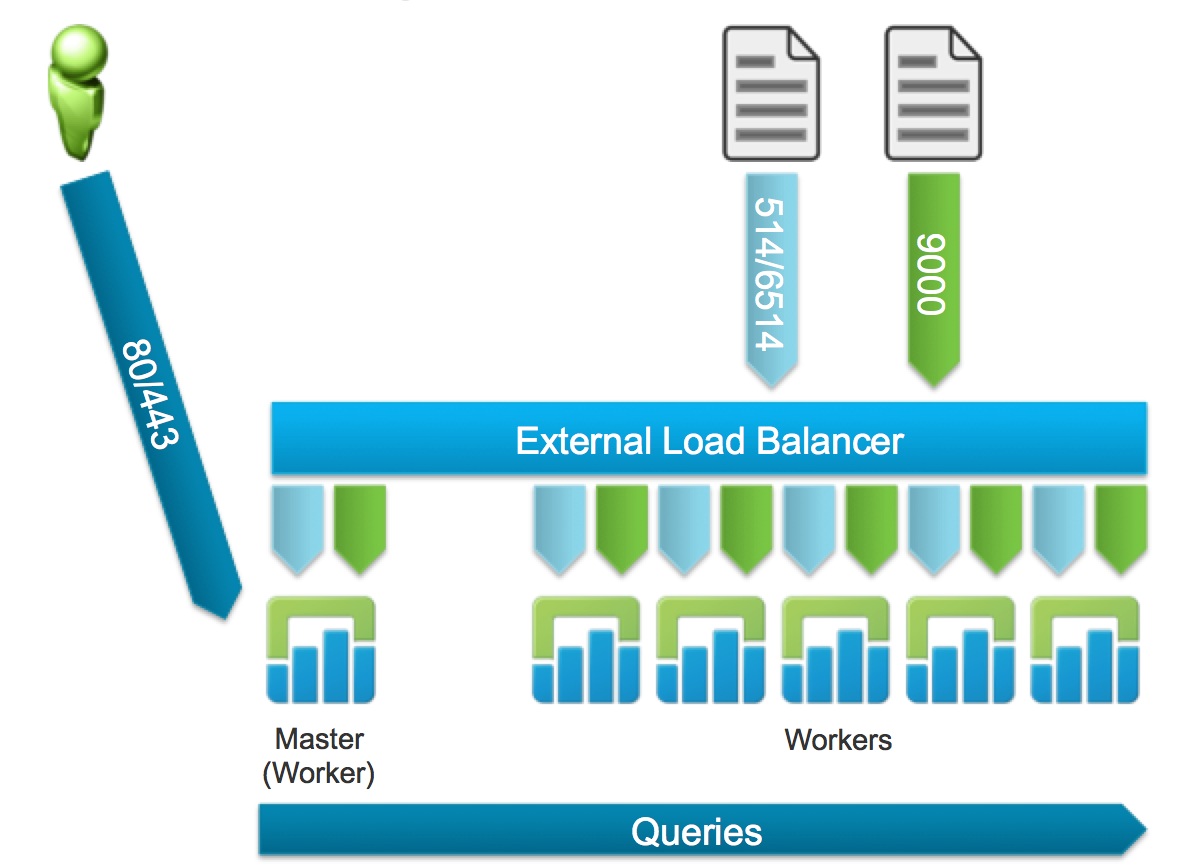
NOTE: While six is the maximum number of nodes supported today, the hard limit is set at 16 within the UI. The primary reason for this is because while the UI strongly suggests using large sized Log Insight instances in cluster mode, medium sized Log Insight nodes are more ideal for some environments (e.g. blade servers), which in turn requires more nodes.
Summary
- Inputs
- Two pipelines exist: query and ingestion
- The query pipeline is handled via Log Insight’s HTML5 UI
- The ingestion pipeline supports syslog as well as Log Insight’s ingestion API
- Standalone
- A standalone instance was the only supported service type in Log Insight 1.x
- An existing standalone service can be turned into a master service, but not a worker service
- Master
- A master service is created when a new Log Insight instance joins an existing standalone service by turning the standalone service into a master service
- The master service is required for all queries; if the master service is unavailable no queries can take place
- A node running a master service is also running a worker service which means the master node can also handle ingestion
- Worker
- A worker service is created when a new Log Insight instance joins an existing standalone service or existing master service by enabling the worker service on the new Log Insight instance
- A worker is responsible for ingestion
- Data ingested by a worker is only available on that worker so if a worker is unavailable some data may not be available for all queries
- The UI warns when a worker is unavailable
- Cluster
- A single master service is supported in a Log Insight cluster today
- Up to six workers are supported today – a hard limit of 16 workers
- A cluster can be created to support increased ingestion rate, to ensure ingestion HA, and/or to improve query performance

© 2014 – 2021, Steve Flanders. All rights reserved.