
I just concluded my series on Log Insight reference architectures and I wanted to explicitly call out how to properly handle Disaster Recovery (DR) in Log Insight. Read on to learn more!
![]()
If you look at my last Log Insight reference architecture post you will see that I recommend the following architecture for DR:
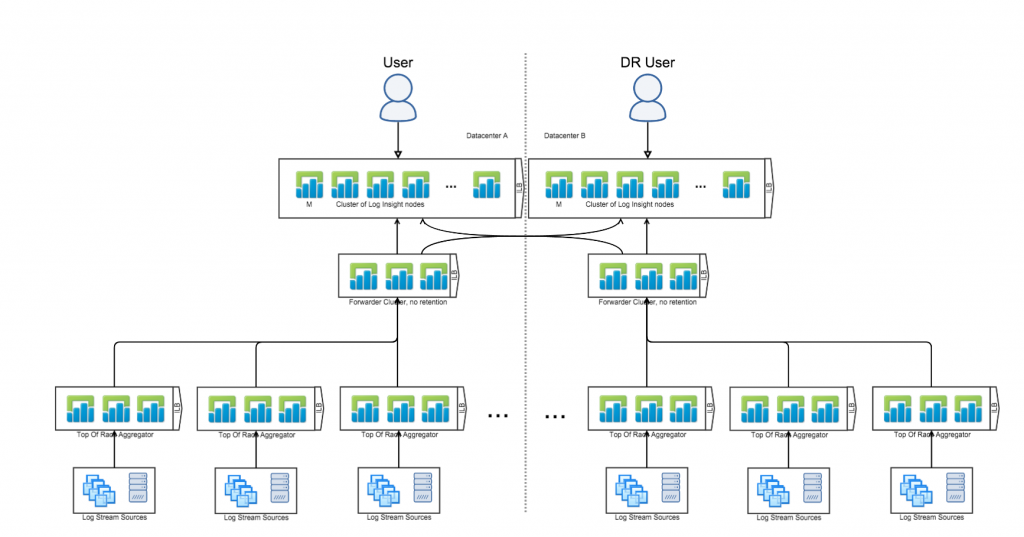
Now you might be wondering if you can do something like this instead:
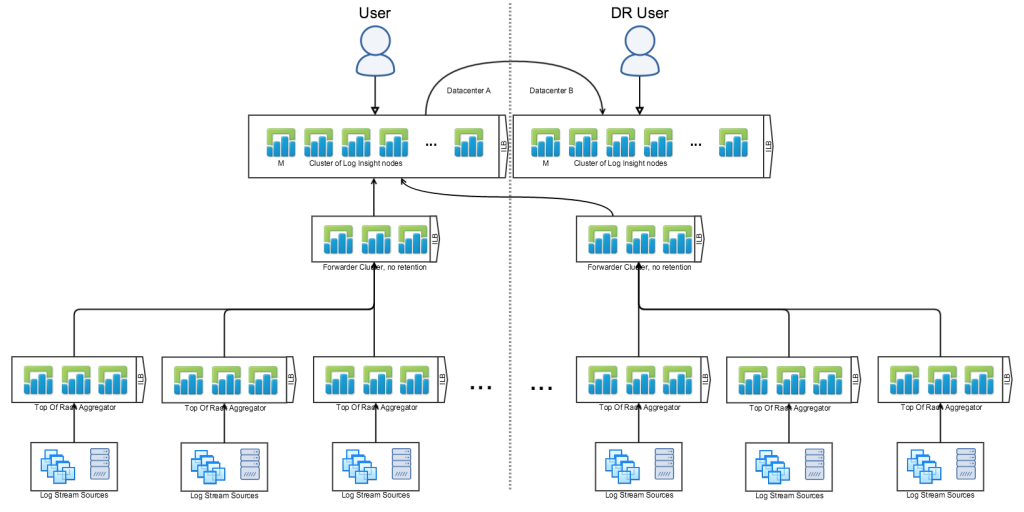
The answer is yes, though it would not be the best practice. There are several reasons for this, but the most apparent is if the primary site is down new events cannot be ingested — this could be mitigated with a DNS change assuming your environment is configured properly.
Another possibility would be a DR architecture like this:
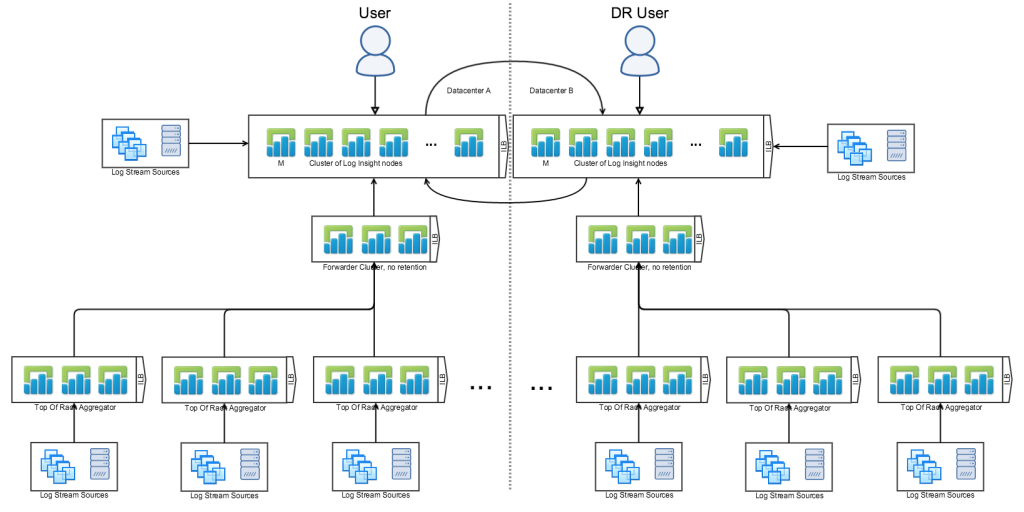
Again, this is possible but not recommended. Two primary reasons stand out in this case:
- Without forwarders in front of the central LI instances it is hard to change/move the central LI instances
- The design clearly has a loop and will be prone to user error
So the best practice is to have all clients log to a Log Insight forwarder and have the Log Insight forwarder forward to two different central Log Insight instances. This architecture prevents loops and provides for immediate failover capabilities in the case of DR.
© 2015, Steve Flanders. All rights reserved.
Steve, I set up a DR configuration, with Tenant aggregators, 2 forward clusters and 2 main LI clusters. Everything is working, but: administration is really difficult and/or time consuming. There is no ‘global view’ of the LI installation, no version control (LI and add-ons), no central agent configuration, some integrations should be configured on the forwarders, some on the central cluster.
Any hints for this?
thanks, Peter
Hey Peter — Thanks for the comment. For a global view, you should vote for this feature: http://loginsight.vmware.com/a/dtd/Ability-to-manage-LI-forwarders-from-central-LI-instance/99040-24427. Your best bet today would be to leverage the TP configuration APIs. I documented the GET ones here: https://sflanders.net/2016/07/21/log-insight-get-configuration-apis/. I hope this helps.