
I was recently deploying a Cloud Foundry instance and was experiencing errors during the deployment. From the several failed deployments, I received the following BOSH error messages:
Error 100: Unable to communicate with the remote host, since it is disconnected.
mysql_node/54: Unable to communicate with the remote host, since it is disconnected.
Error 100: A general system error occurred: Server closed connection after 0 response bytes read; SSL(TCPClientSocket(this=000000000de625e0, state=CONNECTED, _connectSocket=TCP(fd=-1), error=(null)) TCPStreamWin32(socket=TCP(fd=23280) local=10.23.6.17:59642, peer=10.17.0.156:443))
Looking at the events on the ESXi host I saw the following:
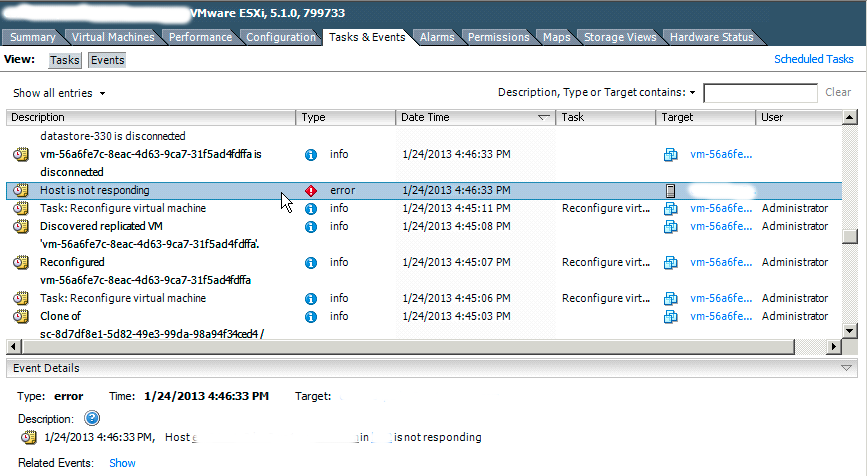
What was causing the issue and how can it be fixed?
I started by checking the logs on the ESXi host. Typically, I search for error or warning messages for a hint as to what is going on. To my surprise, the host had very little messages that day, minimal errors and warnings, and nothing that seemed related to my problem. Next, I decided to check the vCenter Server logs. Again I performed the same exercise of looking for errors and warnings. Below is an excerpt of what I found.
2013-01-24T16:46:02.686Z [06788 warning ‘VpxProfiler’ opID=HB-host-378@199963-81839a33] ClientAdapterBase::InvokeOnSoap: (esx01, vpxapi.VpxaService.retrieveChanges) [SoapRpcTime] took 49523 ms
2013-01-24T16:46:02.686Z [06788 error ‘vpxdvpxdVmomi’ opID=HB-host-378@199963-81839a33] [VpxdClientAdapter] Got vmacore exception: Server closed connection after 0 response bytes read; SSL(TCPClientSocket(this=00000000335d80e0, state=CONNECTED, _connectSocket=TCP(fd=-1), error=(null)) TCPStreamWin32(socket=TCP(fd=6344) local=10.23.6.17:59508, peer=10.17.0.156:443))
2013-01-24T16:46:02.686Z [06788 error ‘vpxdvpxdVmomi’ opID=HB-host-378@199963-81839a33] [VpxdClientAdapter] Backtrace:
–> backtrace[00] rip 000000018018a8ca
–> backtrace[01] rip 0000000180102f28
–> backtrace[02] rip 000000018010423e
–> backtrace[03] rip 000000018008e00b
–> backtrace[04] rip 0000000180048082
–> backtrace[05] rip 0000000180048275
–> backtrace[06] rip 0000000180048760
–> backtrace[07] rip 000000018005d389
–> backtrace[08] rip 000000018011a22c
–> backtrace[09] rip 000000018012528a
–> backtrace[10] rip 000000018011a22c
–> backtrace[11] rip 00000001801a2de8
–> backtrace[12] rip 00000001801aa75f
–> backtrace[13] rip 00000001801aa8dd
–> backtrace[14] rip 00000001801abfd0
–> backtrace[15] rip 000000018019c72a
–> backtrace[16] rip 0000000074b82fdf
–> backtrace[17] rip 0000000074b83080
–> backtrace[18] rip 000000007774652d
–> backtrace[19] rip 000000007787c521
…
2013-01-24T16:46:33.834Z [06788 warning ‘VpxProfiler’ opID=HB-host-378@199963-81839a33] ClientAdapterBase::InvokeOnSoap: (esx01, vmodl.query.PropertyCollector.cancelWaitForUpdates) [SoapRpcTime] took 31147 ms
2013-01-24T16:46:33.834Z [06788 info ‘vpxdvpxdVmomi’ opID=HB-host-378@199963-81839a33] [ClientAdapterBase::InvokeOnSoap] Invoke done (esx01, vmodl.query.PropertyCollector.cancelWaitForUpdates)
2013-01-24T16:46:33.835Z [06788 warning ‘VpxProfiler’ opID=HB-host-378@199963-81839a33] [VpxdHostSync] GetChanges host:esx01 (10.17.0.156) [GetChangesTime] took 80671 ms
2013-01-24T16:46:33.836Z [06788 warning ‘VpxProfiler’ opID=HB-host-378@199963-81839a33] [VpxdHostSync] DoHostSync:0000000012E353E0 [DoHostSyncTime] took 80673 ms
2013-01-24T16:46:33.836Z [06788 warning ‘vpxdvpxdInvtHostCnx’ opID=HB-host-378@199963-81839a33] [VpxdInvtHostSyncHostLRO] DoHostSync failed for host host-378
2013-01-24T16:46:33.836Z [06788 warning ‘vpxdvpxdInvtHostCnx’ opID=HB-host-378@199963-81839a33] [VpxdInvtHostSyncHostLRO] Host sync failed to host-378
2013-01-24T16:46:33.836Z [06788 error ‘vpxdvpxdInvtHostCnx’ opID=HB-host-378@199963-81839a33] [VpxdInvtHostSyncHostLRO] FixNotRespondingHost failed for host host-378, marking host as notResponding
2013-01-24T16:46:33.841Z [06788 warning ‘vpxdvpxdMoHost’ opID=HB-host-378@199963-81839a33] [HostMo] host connection state changed to [NO_RESPONSE] for host-378
2013-01-24T16:46:33.872Z [06788 warning ‘VpxProfiler’ opID=HB-host-378@199963-81839a33] InvtHostSyncLRO::StartWork [HostSyncTime] took 80709 ms
From the above log snippet there are several important pieces of information:
- took <nnn> ms – This message is seen multiple times and suggests some sort of latency between the vCenter Server and ESXi host. You will notice the delays fall in the range of 40-80 seconds, which is significant to say the least.
- Server closed connection after 0 response bytes read – This message means that a heartbeat was not received by the vCenter Server from the specified ESXi host. As you probably know, ESXi sends UDP heartbeats to vCenter Server on port 902 every 10 seconds.
- FixNotRespondingHost failed for host <hhh>, marking host as notResponding – If a heartbeat is not received after a certain amount of time (60 seconds by default) the vCenter Server will mark the host as not responding. If a heartbeat is later received for the host vCenter Server will re-attach the host.
Now that we know what is going on, the question becomes why wasn’t the heartbeat received? This question is a lot harder to answer.
A common place people start with for troubleshooting such issues is searching the KB articles based on error messages and log messages. A quick search turned up:
- KB 1029919 – This article suggests ensuring that firewall ports are opened appropriately between vCenter Server and the ESXi hosts (ports 443 and 902 specifically), something I was sure was not an issue.
- KB 1005757 – This article suggest increasing the heartbeat timeout limit on vCenter Server. While this might fix the issue it does not explain the underlying issue causing the delay and is something I would avoid if at all possible.
The next common place is to search the VMware communities. A quick search turned up the following relevant threads:
- http://communities.vmware.com/message/2180086 – Same as KB 1029919.
- http://communities.vmware.com/message/2083633 – Suggested restarting management services, which did not help in my case.
- http://communities.vmware.com/thread/419936 – Suggested separating the Inventory Service from vCenter Server. This is an interesting suggestion since no KB article seems to exist stating this as an issue. In my case vCenter Server was running on a dedicated RAID 1 with SSDs so hard drive contention should not have been an issue.
At this point most people would likely open a support case. While I did at this point as well, I also decided to use some logic to try and figure out the problem. Since the ESXi host logs were clean and I knew the environment was running on dedicated hardware including compute, network, and storage I figured the issue had to be with vCenter Server. With the vCenter Server logs only displaying the information listed above I decided to take a look at the operating system. I began by looking at the the vCenter Server performance metrics for the vCenter Server in question. What I noticed was that the CPU utilization around the time of the deployment was pegged at >95% for a significant amount of time. In addition, network utilization was also high. As such, I decided to fire up perfmon on the vCenter Server and perform another deployment to confirm the findings. As expected, during deployments the CPU utilization was well over 95% and often at 100% utilization and network utilization was also high. Based on this information I assumed that CPU was a bottleneck and may be responsible for the missing heartbeats. Though uncommon CPU constraints can cause networking as well as disk issues. UDP traffic is especially sensitive to resource issues and may be dropped under load. As such, I decided to increase the number of CPUs and the issue disappeared!
For those interested, VMware support had nothing to offer on the issue, but with the information of resource contention I provided they agreed with my assessment and proposed resolution. One final piece of information you may be interested in was how a Cloud Foundry deployment could peg a vCenter Server instance if the vCenter Server was sized appropriately. In my particular case the issue was the number of compilation VMs specified in the Cloud Foundry manifest. I will be covering more on Cloud Foundry in the future so stayed tuned!
© 2013, Steve Flanders. All rights reserved.