
After covering the new scale-out and Windows agent features available in the Log Insight 2.0 beta, it is important to understand how to load balance traffic across a Log Insight cluster. I will cover why using a load balancer is important, what to consider when load balancing, high-level load balancer configuration, and how to balance load for the three primary ways to get data into Log Insight.

Why Load Balance?
In my post about scale-out, I discussed how load balancing allows for:
- Single management point – without a load balancer, syslog traffic would need to be manually distributed across the nodes in a Log Insight cluster
- Ingestion HA – if any Log Insight node becomes unavailable the load balancer can distribute the load to other nodes in the Log Insight cluster
Another important reason to use a load balancer is to ensure that retention between nodes is similar. If traffic is manually balanced then it is likely to become unbalanced over time where some nodes receive more traffic than others. When this occurs, the nodes with higher traffic will not be able to retain messages for as long as systems with lower traffic. This can lead to queries that only return partial results. Of course, this should only impact the oldest data unless the cluster is significantly imbalanced, but it is an important consideration. I will cover more on load imbalance in a future post.
Load Balancer Considerations
While Log Insight does not care which load balancer is used, it is important to understand the functionality that is required to load balance syslog traffic. This includes:
- UDP – assuming you are sending events over UDP (the standard for most systems today), you need a load balancer that supports UDP traffic.
- TCP – syslog TCP connections are often, what are referred to as, “long-lived” TCP sessions. This means unless the syslog process on the client is restarted or there is a network interruption between the client and the server, the client will establish and keep open a connection with the server (or in the case of a Log Insight cluster, a single node in the cluster). This can lead to cluster imbalances over time (more on this in a future post).
- Algorithm – the default load balancer algorithm is typically round robin. To address potential load imbalance in the base of Log Insight node maintenance, using the least connections algorithm is recommended.
- Connections – it is important that the load balancer used is capable of supporting the number of connections required for your environment. For a full-scale cluster, some load balancers are not capable of handling the combination of the number of connections with the number of events sent per connection resulting in dropped messages.
- Throughput – syslog traffic is light and traffic for a full-scale cluster only pushes about 200MB/s. This rules out developer licenses for many load balancers.
- SNAT – while not specific to syslog traffic, it is important to note that unless the load balancer is also acting as a router that you will need to configure SNAT (Source NAT) for the traffic to be passed properly.
Load Balancer Configuration
In terms of load balancer configuration, you need to create at least one virtual IP (you can create more if you desire, but this is not necessary), and configure a virtual server that in turn requires a pool for each port/protocol combination that you require for ingestion traffic. In Log Insight 2.0 beta, the following port/protocol combinations are supported:
- UDP/514 – Syslog
- TCP/514 – Syslog
- TCP(SSL)/1514 – Syslog
- TCP/9000 – Ingestion API
- Used by the Log Insight Windows agent where it is referred to as the cfapi
- Important: This is TCP/9000 and not HTTP/9000
NOTE: All the ports/protocols you plan on using need to be configured on the load balancer. If you expect to use all ports/protocols at some point in the future then it is recommended to configure them all from day one.
For all of the above port/protocol combinations, all nodes in the cluster should be configured in the associated pool.
NOTE: The recommendation is to create a pool for each virtual server so that health checking can be enabled on a port/protocol basis.
In addition to the above ingestion traffic ports/protocols, Log Insight web traffic can also be configured on the load balancer although this is not required. The reason why you may want to do this is if you want to have the same FQDN for ingestion and query traffic. If web traffic is configured on the load balancer then it should be configured for the following ports/protocols:
- HTTP/80 – Web
- HTTPS/443 – Web
Again, a unique pool should be created for each web port/protocol, but only the master Log Insight node (i.e. the first node in the cluster) should be added to the pool as only the master node serves web/query requests.
NOTE: If worker Log Insight nodes are added to the web pools then the HTML 5 web interface may appear unavailable to some users.
When you are done, you should have the following configured on your load balancer:
- At least 1 VIP
- At least 1 and up to 4 ingestion virtual servers
- The same number of pools as virtual servers for ingestion (1-4)
- Optionally 2 virtual servers for web
- The same number of pools as virtual servers for web (0-2)
Balancing Ingestion Traffic
Log Insight supports ingestion of events in three primary ways outlined below. For each, the recommendation is to configure clients/relays to send traffic to Log Insight using a FQDN so the underlying IP can be changed over time.
Syslog protocol
Assuming your clients/relays are configured to forward events to Log Insight using an FQDN then the FQDN needs to be repointed from the single Log Insight node to the new VIP configured on your load balancer.
IMPORTANT: For clients/relays configured to forward events to Log Insight via FQDN: If clients/relays are configured to send events over the UDP protocol then they should transition to the load balancer VIP very quickly. If clients/relays are configured to send events over the TCP protocol then they will likely not transition to the load balancer VIP until the client’s/relay’s syslog process is restarted. This is due to the way long-lived TCP sessions work (more on this in a future post).
If your clients/relays are configured to forward events to Log Insight using an IP address then your clients/relays will need to be reconfigured to forward events to the new load balancer VIP address. This would be a great time to switch from an IP address to an FQDN to make changes in the future easier.
Ingestion API
The new ingestion API available in Log Insight 2.0 works very similar to the syslog protocol. To work, it requires TCP port 9000 to be configured. The same notes as those provided in the syslog protocol above apply to the ingestion API.
vSphere integration
In Log Insight 1.x, vSphere integration configured ESXi hosts to send traffic to Log Insight using a FQDN if a FQDN was configured properly on the Log Insight virtual appliance prior to running vSphere integration. Otherwise, the IP address of the Log Insight node was used. If you upgrade to Log Insight 2.0 and create a cluster, you will need to reconfigure your ESXi hosts to point to the load balancer VIP instead of the master Log Insight node.
To do this, after you upgrade to Log Insight 2.0 and create a cluster, go to the vSphere integration page and you will see an unconfigure option for each vCenter Server instance for which ESXi hosts remote syslog has been configured. Select the unconfigure option and follow the prompts:
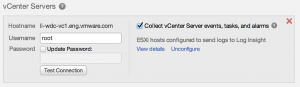
NOTE: If the operation is not 100% successful then the steps below will not work and the unconfigure option will still be presented. Either the issue(s) preventing the unconfigure need to be addressed or the entire vCenter Server will need to be removed by selecting the red ‘X’. Please note that the forced approach of removing the vCenter Server will leave stale remote syslog ESXi configuration on the hosts that could not be unconfigured. This means that a manual cleanup will be necessary on the unsuccessful ESXi hosts.
If the operation is successful, you will have the ability to select a checkbox to configure ESXi hosts. Upon selecting this option, you will have the ability to specify a syslog target (i.e. load balancer) that the ESXi hosts should forward syslog events to.

NOTES:
- The syslog target field only appears in Log Insight 2.0 when a cluster has been configured. For standalone Log Insight 2.0 nodes, this option is not presented.
- Be sure to use a FQDN for the load balancer VIP to make future IP address changes easier.
- Once the syslog target has been set, it cannot be changed without first unconfiguring the ESXi hosts.
© 2014 – 2021, Steve Flanders. All rights reserved.