
To wrap up this series, my last post will list the top four Log Insight reference architectures. Read on to learn more!
![]()
CREDIT: First off, shout out to Alan Castonguay for putting together this information!
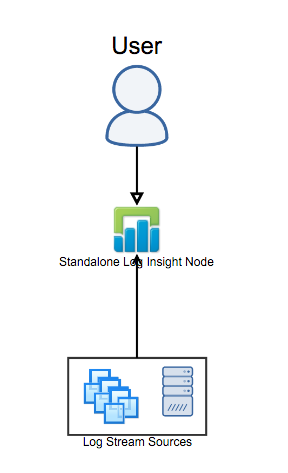
Standalone Node (No HA)
The most basic Log Insight reference architecture is where you have a single Log Insight node and users/devices — including the Log Insight agent — connect directly to it. This configuration is common for proof of concepts, some test environments and some small environments where HA is not required. In general, this architecture is not recommended for production environments — see the next reference architecture instead.
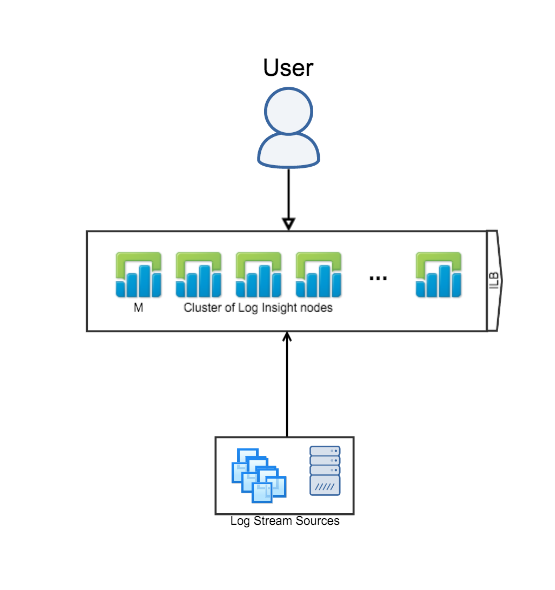
Single Cluster (Ingestion + Query HA)
The next logical Log Insight reference architecture is where you have a single Log Insight cluster — with the Integrated Load Balancer (ILB) configured — and users/devices– including the Log Insight agent — connect directly to the ILB. This configuration is common for production environments in either a single datacenter. In general, this architecture is not recommended for production environments with multiple datacenters — see the next reference architecture instead.
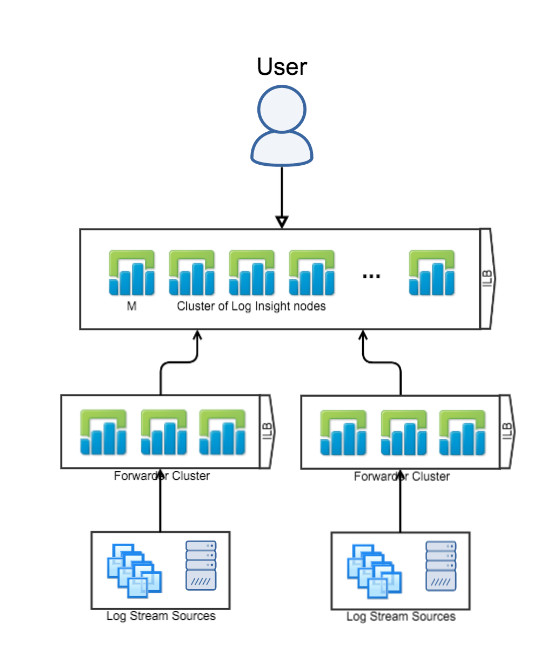
Cluster with Forwarders
(Ingestion + Query HA)
The next logical Log Insight reference architecture is where you have a single, central Log Insight cluster — with the Integrated Load Balancer (ILB) configured — and one or more Log Insight forwarder clusters — with the Integrated Load Balancer (ILB) configured. In this configuration, devices — including the Log Insight agent — connect directly to the local Log Insight forwarder ILB, each Log Insight forwarder is configured to forward events to the central Log Insight cluster, and users connect directly to the central Log Insight cluster ILB. This configuration is common for production environments with multiple datacenters. In general, this is the most common reference architecture, but some environments require even more availability — if more availability is desired, see the last reference architectures.
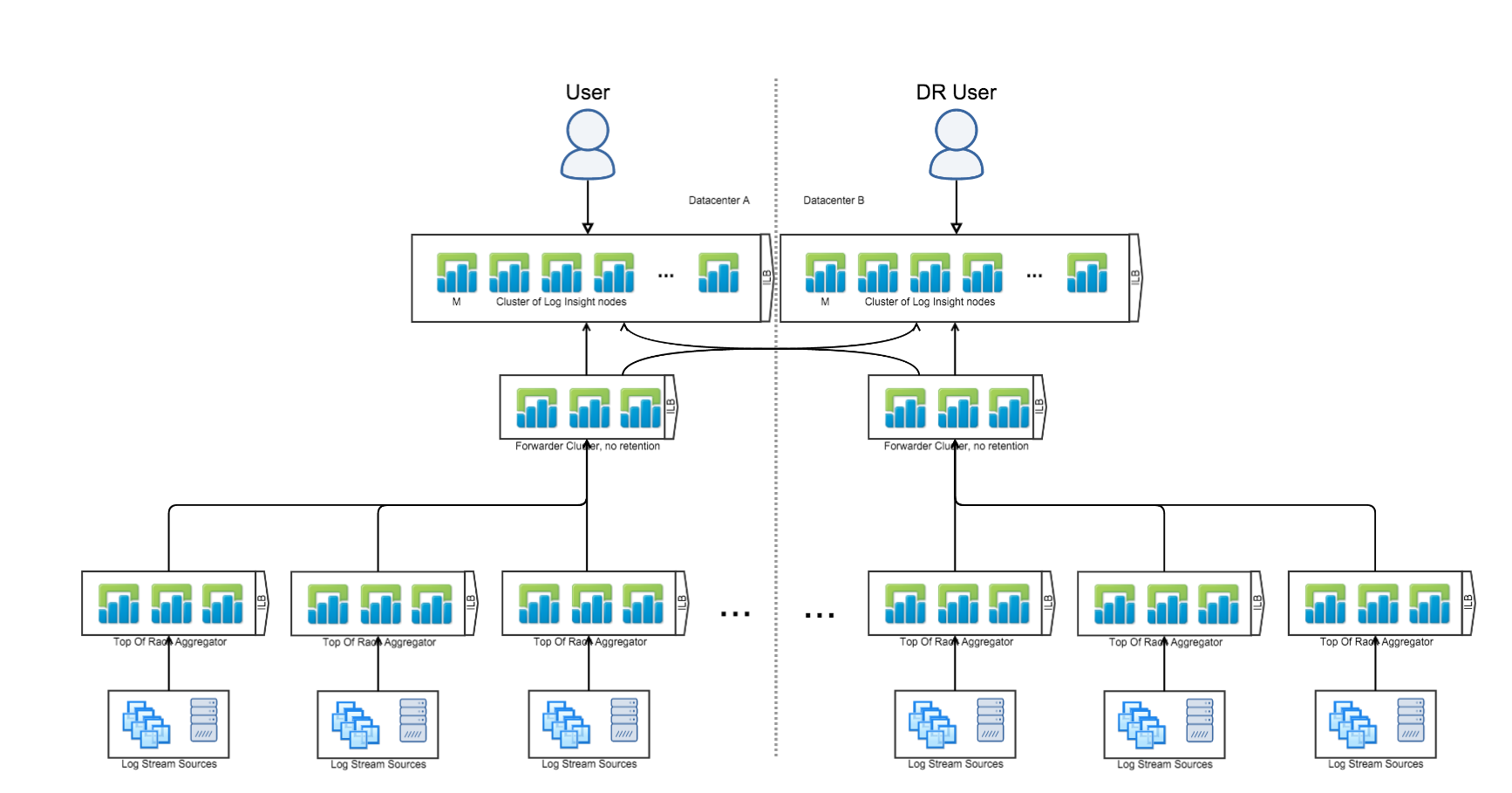
Cross-Cluster with Forwarders
(Ingestion + Query + Data HA)
The last Log Insight reference architecture is where you have two, central Log Insight clusters in different datacenters — each with the Integrated Load Balancer (ILB) configured — and one or more Log Insight forwarder clusters — with the Integrated Load Balancer (ILB) configured. In this configuration, devices — including the Log Insight agent — connect directly to the local Log Insight forwarder ILB, each Log Insight forwarder is configured to forward events to the both central Log Insight clusters — also note that nested forwarders are also supported, and users connect directly to the primary central Log Insight cluster ILB. This configuration is common for production environments that require data HA (aka active DR). Note that this configuration is overkill for most environments, but does provide the highest level of availability.
Summary
As you can see, there are a few different ways to deploy Log Insight depending on the business requirements for the environment. In general, a standalone instance is for POCs/test environments only, a cluster is the minimum requirement for production environments, a cluster with forwarders is the recommended requirement for production environments especially those with multiple datacenters and dual central clusters with forwarders is recommended for environments that require the highest level of availability.
© 2015, Steve Flanders. All rights reserved.
Hi, so I’m looking at deploying “Cross with Forwarders
(Ingestion + Query + Data HA)”, does this design mean that both the collector clusters have the data twice? Just thinking that this means a large storage requirement. Wondering if this is the only way to provide cross site protection?
Hey Chris — That list picture shows three tiers of LI clusters. The top tier represents the active-active DR layer — events are 100% duplicated between those two clusters. The middle tier represents a “domain” (typically a data center) to aggregate events (typically before sending over a WAN) — events are local to the “domain”. The bottom tier is optional — many people do not have a bottom tier — but can be used as a “sub-domain” (could be a department or an infrastructure unit such as a Vblock) — events are local to the “sub-domain”, but replicated and stored in the “domain” as well as the top tier. If you need data HA at the top tier then your only options are the reference architecture provided, a replication mechanism like SRM (active-passive), or a replication mechanism that requires manual intervention. I hope this helps.
Hi Steve, thanks for a great article! Could you share your thoughts on what is the benefit of using one central cluster and two forwarders, as opposed to just two clusters forwarding to each other.
Hey Nick — in general, forwarding between two clusters is not recommended because creating a loop is (highly) possible. In addition, the recommendation is to have dedicated clusters per DC so agent management is central to the DC as well — if you forward between two clusters in two DCs then half of the agents will be configured from one cluster and half from the other. Technically, you could do what you propose, it is just not a best practice today due to issues like the ones I mentioned.
Thanks, Steve. Makes perfect sense!
Hi Steve,
Great article and very informative. I am planning to implement the Cross-Cluster with Forwarders (Ingestion + Query + Data HA) design for that extra availability. I do have one question on how to handle an SRM event.
If Datacenter A (DC-A) goes down. SRM moves 300 VMs over to Datacenter B (DC-B).
The SRM’ed VMs still point to the DC-A Forwarder Cluster.
How do we get the 300 VMs to point at the DC-B Forwarder Cluster instead?
As a note because the Forward Cluster would be in our management cluster it does not have the SRM service, moving it is not an option. My thoughts were to use a GTM that would redirect to the DC-B Forward Cluster. Do you feel this would work or any other ideas?
Thanks in advanced for any help!
Hey Jay — the easiest solution would be to leverage DNS and perform a DNS switchover as part of the event.