
Now that the basic components of Log Insight are known, I would like to cover the evolution of Log Insight topologies as well as the high availability. Read on to learn more!
![]()
Standalone Server/Forwarder (all versions)
Where most people start is with a standalone Log Insight instance. Every version of Log Insight has supported this topology. Note while this topology is great for POCs or dev/test environments, it is not recommended for production environments as it does not provide any high availability (HA).

Clustered Server (2.0)
Log Insight 2.0 was the first release to support clustering. The architecture called for a 3-node cluster of medium or large VMs with an external load balancer configured in front of it. The best practice was to point all traffic to the external load balancer and the configuration required that ingestion traffic go to all nodes, but query traffic only go to the cluster master node. This configuration resulted in ingestion HA.
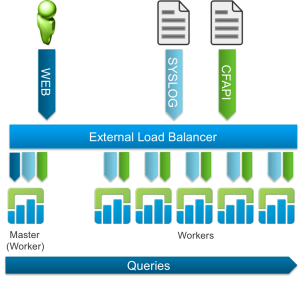
Clustered Server/Forwarder (2.5)
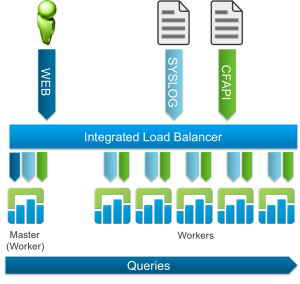
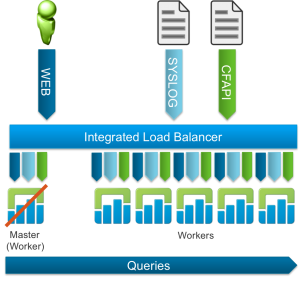
Log Insight 2.5 introduced two changes to cluster management. First, an integrated load balancer was offered, which provided several benefits over an external load balancer. Second, event forwarding was introduced. Neither of these changes really changed the topology diagram of clustering very much. Note the best practice and only supported load balancing technique from Log Insight 2.5 on-ward is via the integrated load balancer.
Clustered Server/Forwarder (3.0)
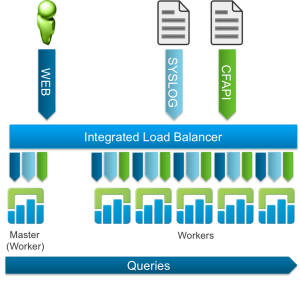
Log Insight 3.0 introduced query HA providing yet another reason to cluster a Log Insight deployment. Note that query HA is automatically configured post-upgrade if using the integrated load balancer (automatic configuration would not occur with an external load balancer). Again, the topology looks very similar.
Ingestion HA (2.0)
When Log Insight clusters were first introduced they supported ingestion HA. In short, you could lose any node in a cluster and ingestion would continue to function. With Log Insight 2.5, the integrated load balancer was highly available as well to ensure ingestion HA.
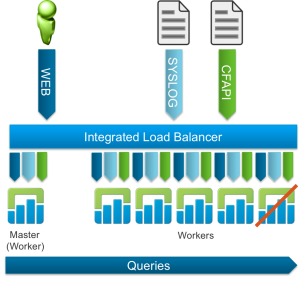
Query HA (3.0)
With the introduction of query HA in Log Insight 3.0, any node could be lost and queries, including user alerts, would continue to function. Due note, some functionality is lost while the master node is offline (e.g. the Administration > Cluster page is not available).
Data HA (TBD)
It is important to note that data HA is not available within a single cluster today. This means if a node is down then all data on that node is unavailable. In this state, the UI does provide a warning that results may not be complete. As soon as the node comes back online the events can be queried again.
While data HA within a cluster is not offered today, data HA can be achieved through a DR architecture — more on this in a future post.
Summary
It is common to start with a standalone Log Insight instance, but a cluster is recommended for production workloads. A Log Insight 3.0 cluster provides both ingestion and query HA. Next up, I would like to talk about greenfield and brownfield deployments as well as security considerations.
© 2015 – 2021, Steve Flanders. All rights reserved.