
In Log Insight 2.0 a scale-out feature was introduced. The best practice when using scale-out is to configure an external load balancer in front of the cluster and send all ingestion traffic (i.e. syslog and ingestion API) to the load balancer instead of directly to a node. The reason for this best practice is to assist with balancing data across nodes and also to provide ingestion high availability. In this post, I would like to discuss why data may not be balanced across a Log Insight cluster whether a load balancer is used or not.

What does a data imbalance look like?
If you go to the Administration > System Monitor > Statistics page you can quickly notice a data imbalance if you look at the syslog and/or API rates per node:
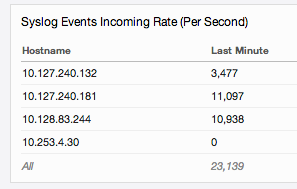
or the total number of events per node:
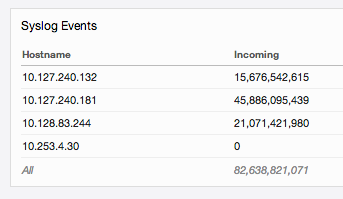
If the numbers are similar between nodes then the traffic is balanced. If the numbers are significantly different on one or more nodes then you have a data imbalance. It is important to note that nodes will never be perfectly balanced, but large discrepancies between nodes can be a cause for concern.
Why is a data imbalance undesired?
The primary reasons why you want to avoid data imbalance are to:
- Stay within configuration maximums per node (e.g. to avoid dropped events)
- Ensure consistent retention across nodes (e.g. for querying or compliance reasons)
Why is data imbalanced?
Data may be imbalanced for a variety of reasons including:
Manually balancing load across nodes (i.e. not using a load balancer)
When in scale-out mode an external load balancer should always be used. For more information, see this post.
Syslog forwarder(s) sending a large number of events per second
Load balancers typically balance traffic on a per-connection (i.e. client) basis. To address devices sending a large number of events per second (e.g. syslog forwarders), message-based load balancing is required. While some load balancers support messages-based load balancing (e.g. F5), the configuration can often be challenging if not natively supported by the load balancer (syslog is not natively supported).
Long-lived connections (i.e. using the TCP protocol for syslog ingestion)
During a maintenance or upgrade operation, a Log Insight node will go offline and will not be able to process ingestion for some period of time. If using an external load balancer then the load balancer can be configured to remove a node from the pool or in the case of unplanned downtime, the load balancer can determine a node is unavailable via a health check. When a node is removed or fails a series of health checks, the load balancer will balance the incoming load across the remaining nodes based on the defined load balancing policy. When the node is added back into the pool or is determined healthy again via a health check, new traffic can be sent to that node. The key word in the previous sentence is *new* traffic.
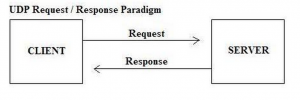
If you are sending events over UDP then *new* traffic should happen almost immediately as UDP traffic is not stateful. This means that every UDP syslog event sent is a unique connection. Visually, this looks something like the following (where request is a single syslog event):
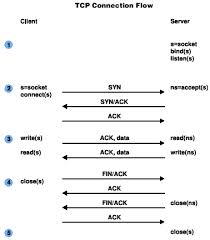
In the case of syslog sent via TCP, it is very common for a client to keep a persistent connection open at all times. This is because events are sent frequently (usually at least one every five minutes) and TCP connections are stateful. This means that while new *data* is being sent, it is not new *traffic* as it is coming in over an existing connection. Visually, this looks something like the following (where steps 4 and 5 never happen because step 3 is continuous):
Expanding the cluster
Let’s say you start with a 3-node cluster and then you exceed the capacity of the 3-node cluster and you need to expand to four or more nodes. When you add the new node, data will be imbalanced if you are using syslog TCP due to the long-lived session issue described above.
What about the Log Insight Windows agent?
The Log Insight Windows agent, just like syslog traffic, should be configured to send traffic to an external load balancer when scale-out is used. This means that the agent could suffer from the syslog forwarder issue described above depending on the number of events per second being generated on the Windows device the agent is monitoring (though this should be rare as typically the Windows device is a client and not a syslog forwarder).
As for long-lived connections, while the agent does use TCP connectivity, it natively has a feature to reconnect the session through the use of the reconnect configuration parameter:
[server] proto=cfapi hostname=loginsight port=9000 ; Force reconnect agent every 30 minutes. reconnect=30
By default, this parameter is set to 30 minutes, but this can be changed as desired.
Summary
As you can see, ensuring data balance is important. Given how most load balancers function, data imbalance in Log Insight is possible if you are using TCP syslog connections for ingestion. Other important things to note are:
- If you are not forwarding events to Log Insight through syslog aggregators then the impact of data imbalance can be mitigated though data retention may still be a concern.
- If you are forwarding events through syslog aggregators and/or you care about data retention then you should either manually fix the data imbalance on the load balancer or consider using message-based load balancing.
- You could consider using only UDP connections for ingestion, however if you are using TCP you likely care about delivery confirmation (e.g. compliance reasons or WAN connectivity).
- The Log Insight Windows agent must follow the rules of the external load balancer, but does not suffer from the long-lived TCP session issue as it reconnects every 30 minutes by default.
Update: Added the Expanding the cluster section.
© 2014 – 2021, Steve Flanders. All rights reserved.
Steve,
Is is possible/supported to have a cluster with something like 3 nodes load-balanced in San Francisco, a node in London collecting local log messages there and another node in Singapore collecting local log messages there? Clearly this could create an imbalanced cluster but if someone understands the pitfalls you describe here and they are willing to accept the drawbacks, would the clustered Log Insight instance function with the latencies and imbalances involved?
Hey Greg, Absolutely! Data imbalance can be a problem, but if you know what you are doing it has some potential benefits as well. Stay tuned for a blog post on the benefits 😉